Local-RAG-Project-v2: a tiny, portable RAG workbench
A local-first Retrieval-Augmented Generation (RAG) app I can clone onto any machine, run fast, and evolve over time—without pretending it’s a full enterprise platform.
The vibe that started it origin story
Some projects start with a problem statement. This one started with a vibe:
“I want a tool I can keep in my pocket, carry to any machine, and keep leveling up—without turning it into an enterprise science fair.”
That’s the heart of Local-RAG-Project-v2: a local-first Retrieval-Augmented Generation (RAG) app that I can clone anywhere, run fast, and evolve over time—while still forcing myself to think like an architect, even when the stakes are “just a local project.”
And yes: I built it because it sounded fun.
Why build a local-first RAG at all?
RAG is one of those patterns that feels magical the first time you see it work:
- You drop in a pile of documents.
- The app learns how to find the right parts.
- Then it answers questions using your content—grounded in what you actually provided.
Now add two constraints that make it way more interesting:
Keep it local
Privacy + speed + control. Your data stays where you keep it.
Keep it lightweight
Portable, hackable, and not pretending to be a platform.
So this project became my “RAG workbench”: something I can run on a laptop, desktop, or a random dev box—no ceremony required.
The promise
At a high level, Local-RAG-Project-v2 is designed to do one job well:
It’s intentionally not trying to solve every production concern. It’s trying to be:
- a clean reference implementation
- a learning engine
- a foundation for experiments
- a tool that stays fun
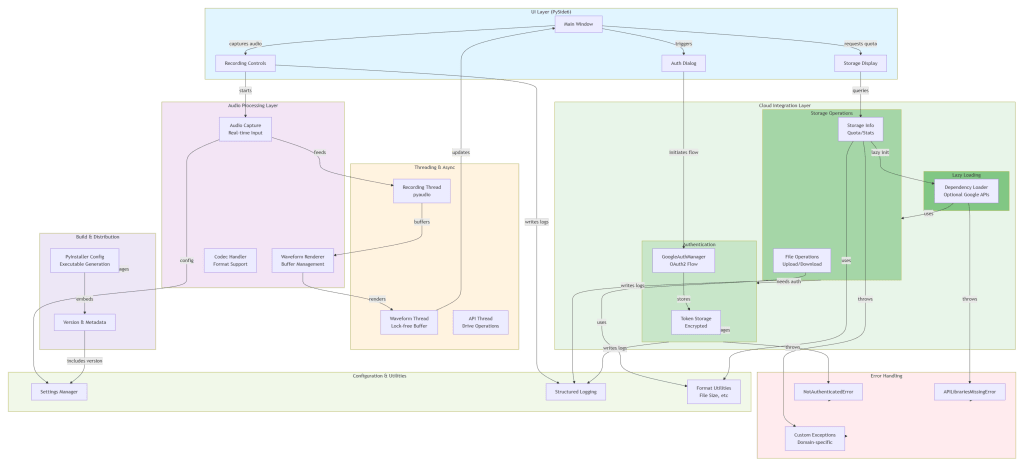
The moving parts (plain English) system map
The system breaks into a few clean responsibilities—because even small projects deserve clean seams.
Read files from local folders, extract/normalize text, split into chunks (with overlap), and deduplicate where it makes sense.
Each chunk becomes a vector embedding—basically a “meaning fingerprint.” Semantic search becomes concept matching, not keyword matching.
Embeddings land in a vector database (or index). Options include FAISS for local speed (plus other local-friendly stores). The important part: the index persists, so you don’t rebuild the universe every run.
On query: embed the question, run similarity search, pull back top chunks (top-k), and optionally use strategies like MMR to reduce redundancy.
The model speaks only after it’s handed context: system instructions, your question, and retrieved chunks (“truth anchors”).
Tools live or die by whether you actually use them. Keep the loop simple:
The flow that makes it feel like a superpower
Here’s the mental model I keep coming back to:
That’s it. No cloud dependency required. No waiting on a remote index. No mystery about where the data went.
The “architect mindset” part: small system, big habits
Local-RAG-Project-v2 is intentionally small, but it’s built to exercise the same architectural muscles I’d use on larger programs:
- Clear boundaries between ingestion, embedding, indexing, retrieval, and generation
- Replaceable components (swap models, stores, chunking strategies)
- Config-first choices so experiments don’t require rewiring the codebase
- Repeatable runs so behavior stays predictable across machines
- Logs/tracing hooks so debugging doesn’t become interpretive dance
The result: a project that’s easy to extend without becoming fragile.
What “lightweight” means (and what it intentionally doesn’t)
Not trying to be
- multi-tenant
- high-availability
- horizontally scalable
- compliance-certified
- enterprise-admin-friendly
- a governance-heavy platform
Trying to be
- portable
- understandable
- fast to iterate
- architecturally clean
- useful immediately
There’s a quiet confidence in building something that knows what it is—and refuses to cosplay as something else.
The practical upgrades that make it feel real
Even in a “fun” project, a few additions dramatically increase usefulness:
- Source attribution in answers — turns “cool demo” into “trustworthy tool.”
- Basic evaluation harness — validates chunking + retrieval quality over time.
- Incremental updates — keeps ingestion snappy as the corpus grows.
- Minimal reproducibility layer — run scripts and optional Docker make “works anywhere” real.
Where this goes next (without losing the fun)
If I were evolving Local-RAG-Project-v2 while preserving its lightweight soul, I’d prioritize:
- Better test coverage — chunking edge cases, embedding batching, retrieval ranking correctness.
- Confidence signals — similarity + agreement heuristics to reduce “sounds right” answers.
- Smarter retrieval strategies — MMR tuning, hybrid search, chunk reranking.
- A “project mode” UX — switch between corpora/indices cleanly.
- Observability that stays light — what got retrieved, why, and what the model saw.
The real win
This project isn’t just a local RAG tool.
It’s a repeatable pattern for building things the right way without needing permission—or a roadmap committee.
It’s proof that you can keep projects small and still:
- design with seams
- build with intention
- leave yourself room to grow
- and enjoy the process
Because the best kind of tool is the one you actually want to open again tomorrow.